
Crosser for Databricks
Ingest pre-processed, ready-to-use data to Databricks
Ingest ready-to-use data to Databricks - from any data source
No matter where your data is located, in the edge, on-premises, in your cloud or in a SaaS service, use Crosser to run batch ETL and Streaming ETL to ingest ready-to-use data to Databricks.

Industry agnostic
Crosser is uniquely positioned in industrial verticals such as manufacturing, process industry, oil & gas, utilities and machine builders/OEMs.
But the platform is equally relevant for any industry vertical including ecommerce, technology, real estate, public sector, telecom, insurance, financial service, retail and many others.

The Data warehouse is not a graveyard. Integrate to & from Databricks with Reverse ETL
Just ingesting data to Databricks is not enough. The data needs to be put in action.
Crosser supports bidirectional integrations from Databricks to any other destinations on-premise/edge, SaaS or in any Cloud.

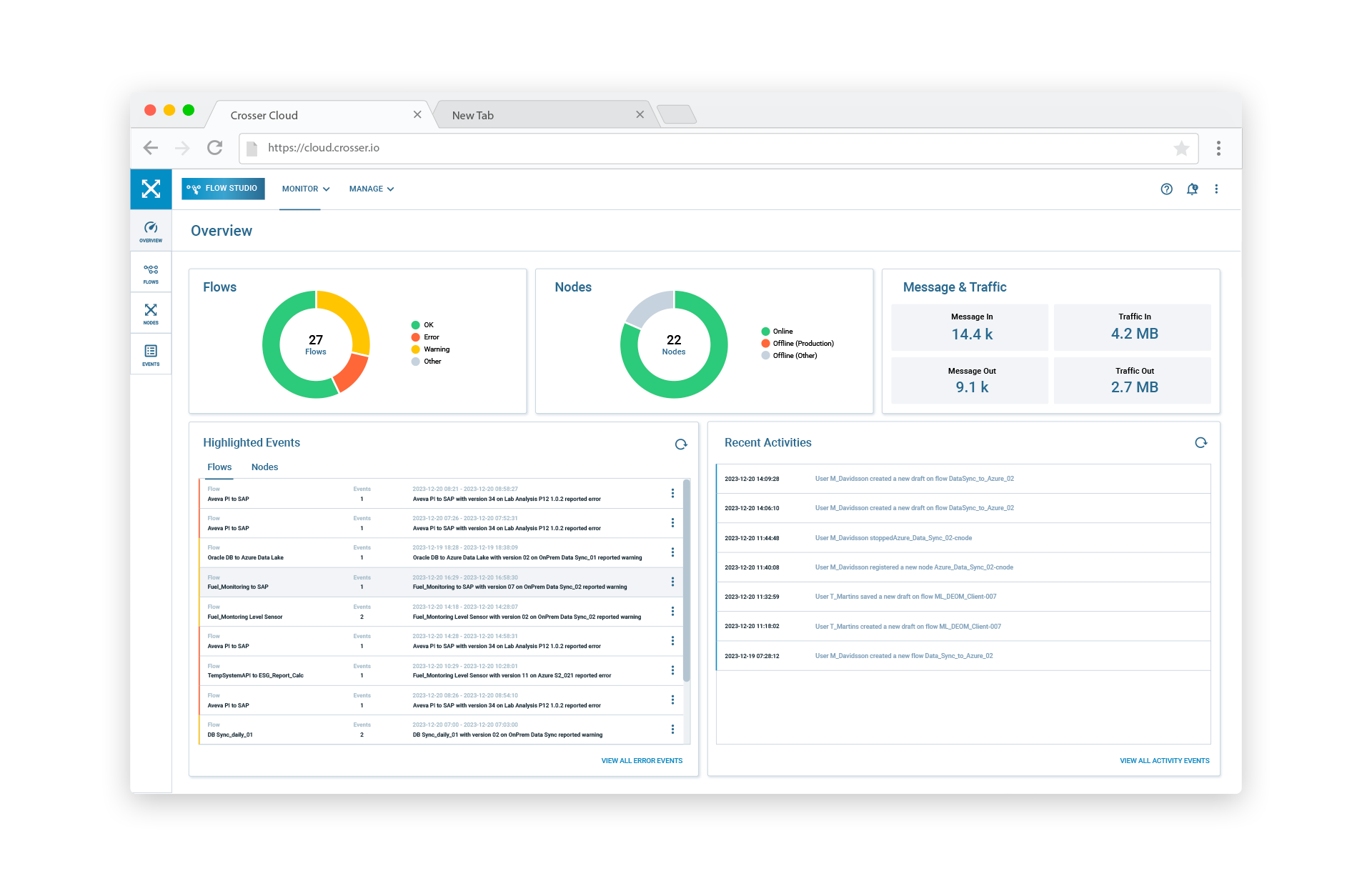
Data Observability for your Data and Data Flows
Monitor, Validate and Control your Data and Data Integration Flows
With Crosser FlowWatch you are on-top of all your streaming, batch and API Data Flows. Wherever they run.
- Flow Monitoring & Alerts
- Data Freshness Monitoring
- Data Validation
- Streaming Data Validation
- Data Volume Validation
- AI/ML model Monitoring
Crosser and Databricks Reference Architecture
Architectural overview of how Crosser and Databricks Setup.

